Zadanie 1 (EDA)
To zadanie zostało wykonane przez - Marek Białousz. Przedstawiono: --- Zapytania w bazach danych postgreSQL oraz elasticsearch. --- Czas wykonania oraz ilość zużytych zasobów. --- Podsumowanie i porównanie użytych baz danych. --- Opis danych oraz instrukcja.
Informacje o danych
Plik zawiera najnowsze dane (luty 2017) Krajowych Statystyk wyszukiwania kodu pocztowego dla Wielkiej Brytanii. National Statistics Postcode Lookup (Latest) Centroids Rozmiar: > 902 MB Ilość: 2593613
Instalacja i konfiguracja oprogramowania
PostgreSQL
Baza, na której odbywały się badania - postrgeSQL. Link do pobrania - TUTAJ.
Jdk
Do badań na bazie elasticsearch potrzebny jest jdk. Link do pobrania - TUTAJ. Konfiguracja zmiennych środowiskowych:
Python
Python będzie potrzebny do uruchomienia skryptów. Link do pobrania - TUTAJ.
PostgreSQL
Import danych
1. Pobrać dane 2. Pobrać skrypt Skrypt trzeba umieścić w folderze z danymi. Jest on potrzebny, ponieważ usunie znaki nie kodowane w windows-1250 w cmd.
py s1.py
pgfutter --pass "[hasło]" --table "test" csv map.csv

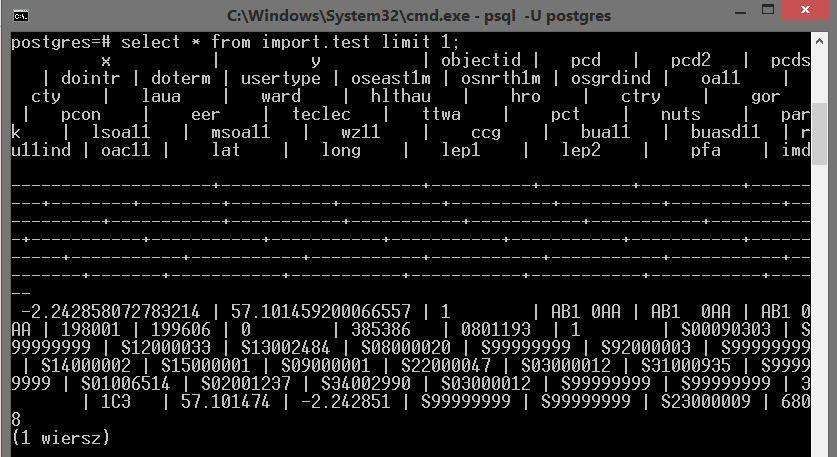
Przykładowy rekord
Uruchamiamy serwer
cd [ścieżka gdzie jest zainstalowany postgreSQL]\PostgreSQL\9.6\bin
psql -U postgres
Polecenie aby wyświetlić przykładowe dane:
select * from import.test limit 1;
Ilość danych
1. Polecenie do wyświetlenia - jaka ilość danych została zaimportowana:
select count(*) from import.test;
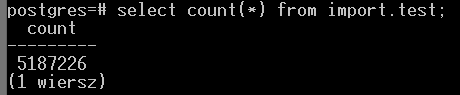
Usuwanie danych
Niektóre kolumny zawierają puste pola np. kolumny ze współrzędnymi x oraz y. Polecenie do usunięcia:
delete from import.test where x='' and y='';

Elasticsearch
Import danych
1. Pobierz plik z danymi - LINK 2. pobierz skrypt. 3. Uruchom skrypt w tym samym folderze, gdzie znajudują się wszystkie dane. (Działanie skryptu - usuwa pierwszy wiersz (nazwy kolumn) oraz zapisuje do pliku map.csv)
py s2.py
cd [ścieżka gdzie pobrano logstash]\logstash-5.3.0\bin
copy [ścieżka gdzie pobrano plik konfiguracyjny]\btc.conf [ścieżka gdzie pobrano logstash]\logstash-5.3.0\bin
copy [ścieżka gdzie znajduje się plik map]\map.csv C:\
logstash -f btc.conf
Przykładowy rekord
Po wykonanym imporcie danych należy wpisać polecenie, które wyświetli przykładowy rekord:
curl -s "http://localhost:9200/test/_search?size=1&pretty=1&filter_path=hits.hits._source"
Ilość danych
Polecenie do sprawdzenia jaka ilość danych została zaimportowanych:
curl -XGET localhost:9200/test/_count
{"count":2593613,"_shards":{"total":5,"successful":5,"failed":0}}
Usuwanie danych
Polecenie usunięcia wszystkich danych, w których objectid = 11 :
curl -XDELETE "http://localhost:9200/test?q=objectid:'11'&filter_path=hits.hits._source"
Wyświetlenie danych
Polecenie wyświetlenia wszystkich danych, w których ru11ind = 6, polecenie:
curl -s "http://localhost:9200/test/_search?pretty=true&q=ru11ind:'6'&filter_path=hits.hits._source
Podsumowanie
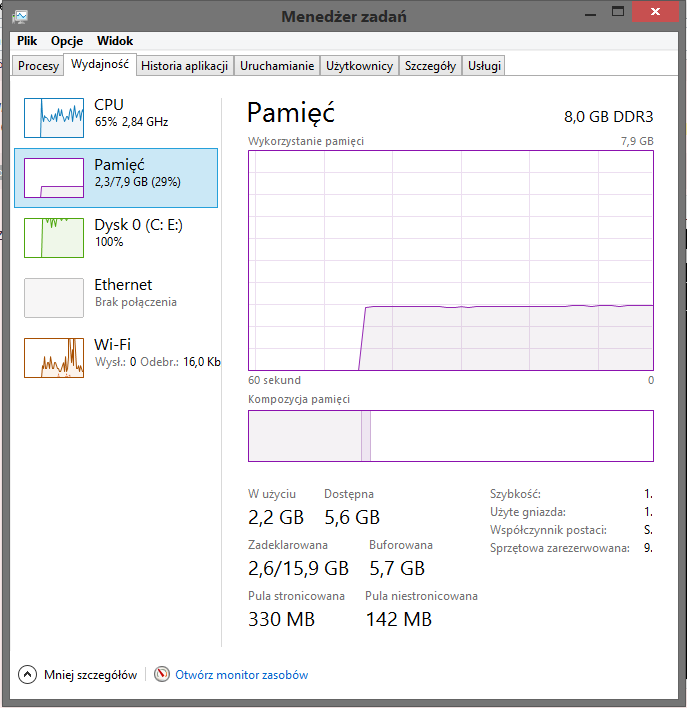
Na podstawie przeprowadzonych badań, można zrobić małe podsumowanie, którego wyniki przedstawiono poniżej:| Nazwa | PostgreSQL | Elasticsearch | ||||||
|---|---|---|---|---|---|---|---|---|
| Czas | CPU | Pamięć | Dysk | Czas | CPU | Pamięć | Dysk | |
| Import danych | 4 min. | 65% | 29% | 100% | 2 godz. 45 min | 100% | 35% | 75% |
| Przykładowy rekord | 1 sek. | 30% | 25% | 0% | 1 sek. | 30% | 30% | 0% |
| Ilość danych | 2 sek. | 30% | 25% | 0% | 1 sek. | 30% | 30% | 0% |
| Usuwanie danych | 2 sek. | 30% | 25% | 0% | 1 sek. | 30% | 30% | 0% |
| Wyświetlenie danych | 10 sek. | 30% | 25% | 0% | 1 sek. | 30% | 30% | 0% |